Recent works imply that the channel pruning can be regarded as searching optimal sub-structure from unpruned networks. However, existing works based on this observation require training and evaluating a large number of tructures, which limits their application. In this paper, we propose a novel differentiable method for channel pruning, named Differentiable Markov Channel Pruning (DMCP), to efficiently search the optimal sub-structure. Our method is differentiable and can be directly optimized by gradient descent with respect to standard task loss and budget regularization (e.g. FLOPs constraint). In DMCP, we model the channel pruning as a Markov process, in which each state represents for retaining the corresponding channel during pruning, and transitions between states denote the pruning process. In the end, our method is able to implicitly select the proper number of channels in each layer by the Markov process with optimized transitions. To validate the effectiveness of our method, we perform extensive experiments on Imagenet with ResNet and MobilenetV2. Results show our method can achieve consistent improvement than state-of-the-art pruning methods in various FLOPs settings.
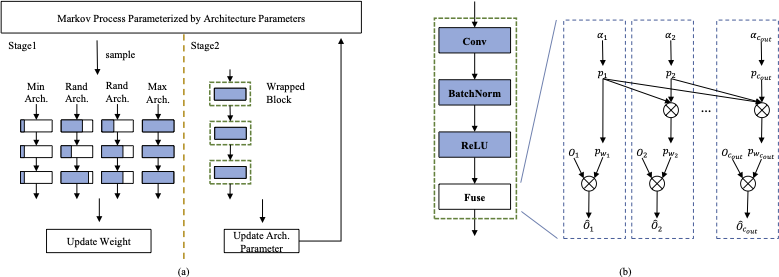
The channel pruning is first formulated as a Markov process parameterized by architecture parameters and can be optimized in an end-to-end manner. Then the training procedure of DMCP can be divided into two stages: in stage 1, the unpruned network is updated by our proposed variant sandwich rule, while in stage 2, the architecture parameters are wrapped into the unpruned network and get updated, as shown in Figure (a). After the optimization, we propose two ways to sample the pruned network.
| Group | Model | FLOPs | Top-1 | Δ Top-1 |
|---|---|---|---|---|
| MobileNet-V2 | Uniform 1.0x | 300M | 72.3 | - |
| Uniform 0.75x | 210M | 70.1 | -2.2 | |
| Uniform 0.5x | 970M | 64.8 | -7.5 | |
| Uniform 0.35x | 59M | 60.1 | -12.2 | |
| MetaPruning | 217M | 71.2 | -0.8 | |
| 87M | 63.8 | -8.2 | ||
| 43M | 58.3 | -13.7 | ||
| AMC | 211M | 70.8 | -1.0 | |
| AutoSlim* | 300M | 74.2 | +2.4 | |
| 211M | 73.0 | +1.2 | ||
| DMCP | 300M | 73.5 | +1.2 | |
| 211M | 72.2 | -0.1 | ||
| 97M | 67.0 | -5.3 | ||
| 87M | 66.1 | -6.2 | ||
| 59M | 62.7 | -9.6 | ||
| 43M | 59.1 | -13.2 | ||
| DMCP* | 300M | 74.6 | +2.3 | |
| 211M | 73.5 | +1.2 | ||
| ResNet-18 | Uniform 1.0x | 1.8G | 70.1 | - |
| FPGM | 1.04G | 68.4 | -1.9 | |
| DMCP | 1.04G | 69.2 | -0.9 | |
| ResNet-50 | Uniform 1.0x | 4.1G | 76.6 | - |
| Uniform 0.85x | 3.0G | 75.3 | -1.3 | |
| Uniform 0.75x | 2.3G | 74.6 | -2.0 | |
| Uniform 0.5x | 1.1G | 71.9 | -4.7 | |
| Uniform 0.25x | 278M | 63.5 | -13.1 | |
| FPGM | 2.4G | 75.6 | -0.6 | |
| SFP | 2.4G | 74.6 | -2.0 | |
| MetaPruning | 3.0G | 76.2 | -0.4 | |
| 2.3G | 75.4 | -1.2 | ||
| 1.1G | 73.4 | -3.2 | ||
| AutoSlim* | 3.0G | 76.0 | -0.6 | |
| 2.0G | 75.6 | -1.0 | ||
| 1.1G | 74.0 | -2.6 | ||
| DMCP | 2.8G | 76.7 | +0.1 | |
| 2.2G | 76.2 | -0.4 | ||
| 1.1G | 74.0 | -2.6 | ||
| 278M | 66.4 | -10.0 |
We compare our method with various pruning methods, including reinforcement learning method AMC, evolution method MetaPruning, one-shot method AutoSlim, and traditional channel pruning methods SFP and FPGM. ll methods are evaluated on MobileNetV2, ResNet18, and ResNet50, in each type of model, we trained a set of baseline model for comparison. From the Table, we can see that our method outperforms all other methods under the same settings, which show the superiority of our method. Note that AMC, MetaPruning and our method train the pruned model from scratch by standard hard label loss.
While AutoSlim adopts a in-place distillation method in which the pruned network share weights with unpruned net and mimic the output of the unpruned net. The groups marked by *> indicate the pruned model is trained by the in-place distillation method. To fairly compare with AutoSlim, we also train our pruned model with the same method. Results show that this training method can further boost the performance, and our method surpasses AutoSlim in different FLOPs models.