Human-Object Interaction (HOI) detection plays an important role in human activity understanding. Most previous methods solely rely on human instance-level supervision and thus cannot effectively disentangle the fine-grained action semantics (e.g., holding while eating). Recently, PaStaNet has proposed to address the problem by explicitly labeling the states of each body part with corresponding human pose and boxes in the images. However, its network structure is very complicated and hard to train and make inferences due to the complex input. In this paper, we propose a novel framework that adopts a transformer-based detector that, besides using HOI labels, only employ human-part state annotations (i.e., without human part box position and human pose). Instead of directly applying discrete human-part labels during classification, we incorporate a language model BERT to transform natural language labels to continuous latent feature vectors and train our model by contrastive loss. Moreover, we can further utilize our trained BERT to train our model with the weakly-labeled dataset without part state labels (e.g., AVA) by language supervision. The experimental results on the HICO-DET dataset demonstrate the superiority of our method in terms of overall mAP (34.0 vs 29.1) and especially mAP of rare classes (31.9 vs 22.6) compared with the state-of-the-art methods.
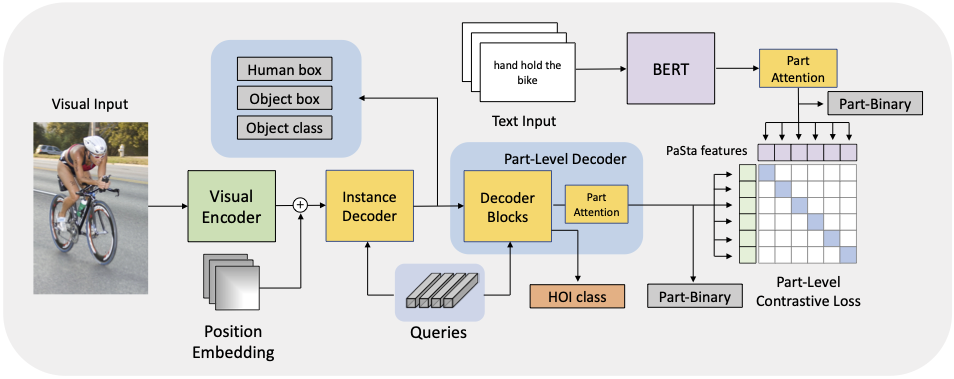
The figure gives an overview of our network architecture, which can be divided into three parts: (1) a visual encoder takes images as input and outputs a set of embedded tokens; (2) the Instance Decoder (ID) decodes human and object bounding boxes with object class; (3) the Part-Level Decoder (PLD) takes the output of instance decoder as the memory input, further decodes PaSta and predicts verbs based on part-level information. Inspired by CLIP, instead of explicitly annotating the PaSta labels by discrete vectors, we adopt the pre-trained BERT obtained from CLIP to implicitly encode them as continuous feature vectors.
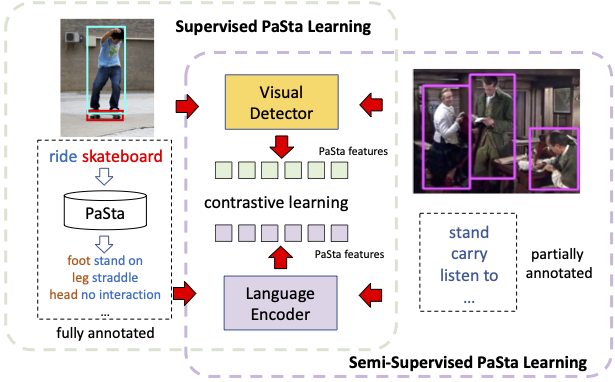
The training pipeline can be divided into two phases: part-Level pretraining, and semi-supervised learning. Notably, we disable the HOI class layer and only use part-level supervision, which will be trained in fine-tuning process.
| Method | Default mAP | Known Object mAP | ||||
|---|---|---|---|---|---|---|
| overall | rare | non-rare | overall | rare | non-rare | |
| TIN | 17.0 | 13.4 | 18.1 | 19.2 | 15.5 | 20.3 |
| DRG | 24.5 | 19.5 | 26.0 | 28.0 | 23.1 | 29.4 |
| HOTR | 25.7 | 21.9 | 26.9 | - | - | - |
| IDN | 26.3 | 22.6 | 27.4 | 28.2 | 24.5 | 29.4 |
| QPIC | 29.1 | 21.9 | 31.2 | 31.7 | 24.1 | 33.9 |
| TIN-PaStaNet | 22.7 | 21.2 | 23.1 | 24.5 | 23.0 | 25.0 |
| QPIC-PCL* | 30.3 | 25.3 | 31.8 | 31.9 | 27.6 | 34.2 |
| QPIC-PCL*-AVA | 30.4 | 25.2 | 32.0 | 32.1 | 27.6 | 34.5 |
| PaStaNet* | 19.5 | 17.3 | 20.1 | 22.9 | 20.5 | 22.5 |
| PCL* | 32.1 | 27.8 | 32.8 | 34.9 | 32.4 | 35.7 |
| PCL | 33.7 | 31.7 | 33.9 | 36.4 | 34.9 | 36.7 |
| PCL-AVA | 34.0 | 31.9 | 34.2 | 36.7 | 35.1 | 36.9 |
In the table, we show the results of various baselines and PCL with its variants, whose rows are marked in green color. The last three rows are our proposed method with PaSta supervision, in which PCL* means the model is directly trained on HICO-DET with PaSta annotations. The model shows significant improvement in the rare HOI class from 22.6 (IDN) to 27.8 with 5.2 mAP, while the overall mAP improved from 29.1 (QPIC) to 32.1 with 3.0 mAP. With the pre-training on HAKE with PaSta labels, denoted by PCL, the overall mAP got further improved by 1.6 mAP from 32.1 to 33.7. Moreover, the mAP in rare HOI classes improved by a large margin by 3.9 mAP from 27.8 to 31.7. Lastly, we performed a semi-supervised training on AVA after pre-training on HAKE. The mAP improves by a reasonable amount in all three metrics and pushes the boundary of the overall mAP to 34.0. Besides, we build a baseline based on QPIC, namely QPIC-PCL*, such that the model can be trained without PaSta annotations. From the table, we can find that our method can still outperform QPIC by 1.2 mAP. With semi-supervised training, denoted by QPIC-PCL*-AVA, the performance got minor improvement with 0.1 overall mAP.